
In case you aren’t familiar with us, Further provides conversational digital sales experiences to prospects looking for senior living. Our platform helps answer prospect questions and drive next steps, such as scheduling a tour or continuing the conversation over SMS. By delivering tailored, engaging experiences, we help senior living communities generate high-quality leads and improve their overall marketing and sales results.
In carrying out these efforts, we also capture a large amount of data and keep it in sync with our customers' CRM systems. At the highest level, we capture marketing, behavioral and conversational data, then we link that information back to who actually moves in.
The move-in prediction algorithm Further has developed uses the inputs of marketing, behavioral and conversational data to then predict the output: who will actually move in.
We will explain in more detail below the data we capture, the way we train our models and the steps that went into validating our results.
The steps to developing this model were:
We capture three different kinds of data that feed into our training models (The Machine Learning Algorithm above)
Marketing & Behavioral Data: Examples of these include time on site, traffic source, pages viewed, keyword clicked etc.
Conversational Data: Conversational data includes factors such as timeline, who someone is looking for, questions asked, whether a tour was requested, etc.
Success Data: We have collected and tracked which visitors turned into a move-in and connected them to the conversational and marketing data through two way CRM integrations.
Tracking the end-to-end customer journey is great, but in order to create an algorithm that would work in a forward looking way, we needed to make sure our information was apples-to-apples across all the prospects we interact with.
All of our customers use Further’s tools in slightly different ways and they all have different sales and marketing stacks. Regardless of the agency, the CRM, Further’s implementation or the website, we need to be able to look at data the same way. This process is called Normalization, and it was the largest challenge to overcome for us to deliver an accurate score.
To give a few examples of things we needed to do before we could look at all prospects within the same lens:
This process allowed us to compare conversations between prospects regardless of the community and from here we were able to start figuring out which attributes to include Vs disregard.
As part of the normalization process, we identified a long list of attributes where we would be able to compare 1:1 across all the prospects we had tracked. We started with a long list of attributes (over 100) and whittled it down to just 47 that we ended up using in our final model. There is a huge amount of testing that goes into attribute selection and we found out the optimal number of attributes to maximize results was this combination of 47. There is a good chance this number will drop even more over time as we continue to improve our approach.
A few of the examples of the attributes we used:
Once the data was normalized, we split it into a training set and a validation set so we could evaluate our accuracy. The training set builds the model, and the validation set verifies the model’s accuracy (the results from the previous post is the training and validation set).
We selected different combinations of attributes and let the machine learning model figure out how to weight each attribute, so we would have the highest accuracy in our prediction. We added and removed attributes and reran this process hundreds of times to figure out the best combination of model and attribute list.
The diagram below does a good job showing how this process works at a high level:
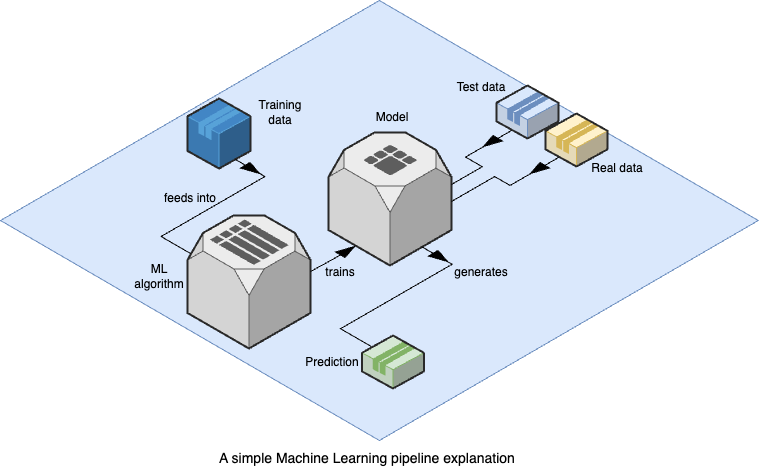
In the end, the best performing approach was a combination of two models running synchronously. If we predict someone will move in, and they don’t, the cost is low. If we predict someone won’t move in, but they do, that is an extremely expensive mistake. So for the purposes of this project, we optimized for making sure there were no False Negatives, that is someone who is likely to move in, but we predict it as unlikely.
The way the score from the model works is to assign a score from 0-100 to each lead. 51% of leads scored less than 20, and that represents just 3% of all move-ins. 82% of leads scored less than 61 and that represents just 24% of all move-ins. Leads with a score of 90+ have a 22% lead-to-move-in conversion rate.
If you read our previous post you have likely seen the results already, but here they are again:
Further's expertise and data is focused on sales and marketing, but this kind of approach to predicting performance can be used in many different functions across senior living. As senior living organizations build out more robust data lakes and invest in analytics, there will be more and more opportunities to leverage machine learning to drive performance.

